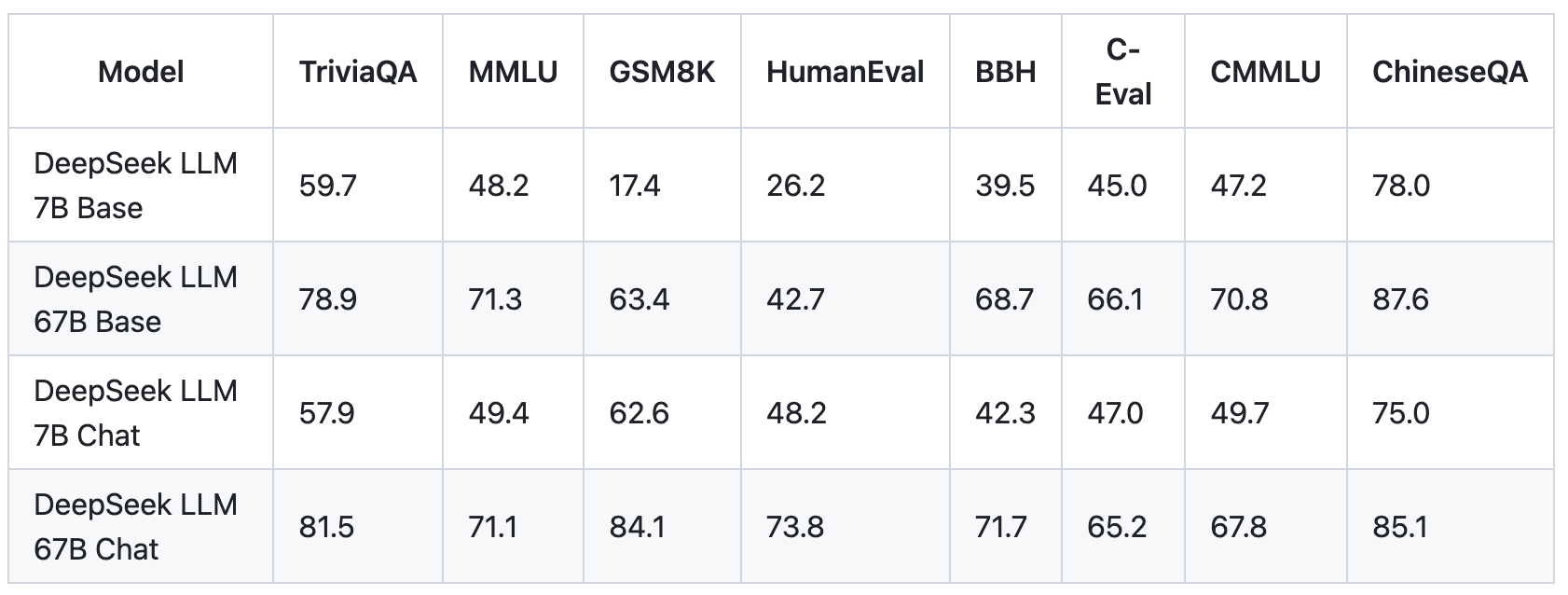
Is DeepSeek better or ChatGPT? Several months earlier than the launch of ChatGPT in late 2022, OpenAI launched the model - GPT 3.5 - which would later be the one underlying ChatGPT. So for those who simply go search fashions, kind in DeepSeek R1, you can set up this mannequin fairly simply. Deepseek is altering the best way we seek for info. The company's privacy coverage spells out all of the terrible practices it makes use of, comparable to sharing your consumer data with Baidu search and delivery the whole lot off to be saved in servers controlled by the Chinese government. DeepSeek might be an existential problem to Meta, which was making an attempt to carve out a budget open source models niche, and it would threaten OpenAI’s short-term enterprise mannequin. To answer this question, we have to make a distinction between providers run by DeepSeek and the deepseek ai china fashions themselves, which are open supply, freely out there, and starting to be offered by domestic providers. The DeepSeek crew seems to have gotten nice mileage out of instructing their mannequin to determine quickly what answer it could have given with lots of time to assume, a key step in earlier machine learning breakthroughs that allows for rapid and low-cost enhancements.
 This might be for a number of causes - it’s a commerce secret, for one, and the model is far likelier to "slip up" and break safety guidelines mid-reasoning than it's to do so in its last reply. And while it’s an excellent model, a big a part of the story is solely that all models have gotten a lot much better over the last two years. While encouraging, there is still much room for enchancment. DeepSeek demonstrated (if we take their course of claims at face value) that you can do greater than folks thought with fewer assets, but you can still do greater than that with more resources. While it was far less than the amount OpenAI spent, it is nonetheless an astronomical amount that you simply or I can solely dream of gaining access to. Anyone may access GPT 3.5 for free by going to OpenAI’s sandbox, a website for experimenting with their latest LLMs. We believe that this paradigm, which combines supplementary information with LLMs as a feedback source, is of paramount importance.
This might be for a number of causes - it’s a commerce secret, for one, and the model is far likelier to "slip up" and break safety guidelines mid-reasoning than it's to do so in its last reply. And while it’s an excellent model, a big a part of the story is solely that all models have gotten a lot much better over the last two years. While encouraging, there is still much room for enchancment. DeepSeek demonstrated (if we take their course of claims at face value) that you can do greater than folks thought with fewer assets, but you can still do greater than that with more resources. While it was far less than the amount OpenAI spent, it is nonetheless an astronomical amount that you simply or I can solely dream of gaining access to. Anyone may access GPT 3.5 for free by going to OpenAI’s sandbox, a website for experimenting with their latest LLMs. We believe that this paradigm, which combines supplementary information with LLMs as a feedback source, is of paramount importance.
Since you are using it, you've little question seen folks speaking about DeepSeek AI, the brand new ChatBot from China that was developed at a fraction of the costs of others prefer it. DeepSeek is a Chinese company specializing in artificial intelligence (AI) and natural language processing (NLP), offering advanced instruments and fashions like DeepSeek-V3 for textual content technology, data evaluation, and more. Both instruments have raised considerations about biases in their information assortment, privacy issues, and the potential for spreading misinformation when not used responsibly. These two architectures have been validated in deepseek ai china-V2 (DeepSeek-AI, 2024c), demonstrating their capability to take care of robust mannequin performance while attaining efficient training and inference. The researchers consider the efficiency of DeepSeekMath 7B on the competitors-degree MATH benchmark, and the mannequin achieves an impressive score of 51.7% with out counting on external toolkits or voting methods. Assisting researchers with complicated drawback-solving duties. It’s optimized for each small duties and enterprise-stage calls for. It’s notoriously challenging because there’s no normal formulation to use; solving it requires inventive thinking to use the problem’s construction.
 All of which raises a query: What makes some AI developments break by means of to the general public, whereas other, equally impressive ones are only observed by insiders? While these high-precision elements incur some reminiscence overheads, their impact can be minimized by way of environment friendly sharding across multiple DP ranks in our distributed coaching system. Throughout all the training process, we did not encounter any irrecoverable loss spikes or must roll again. But none of that is a proof for DeepSeek being at the top of the app store, or for the enthusiasm that individuals seem to have for it. Low-precision training has emerged as a promising answer for efficient coaching (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), its evolution being closely tied to developments in hardware capabilities (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). On this work, we introduce an FP8 mixed precision coaching framework and, for the primary time, validate its effectiveness on an especially giant-scale model.
All of which raises a query: What makes some AI developments break by means of to the general public, whereas other, equally impressive ones are only observed by insiders? While these high-precision elements incur some reminiscence overheads, their impact can be minimized by way of environment friendly sharding across multiple DP ranks in our distributed coaching system. Throughout all the training process, we did not encounter any irrecoverable loss spikes or must roll again. But none of that is a proof for DeepSeek being at the top of the app store, or for the enthusiasm that individuals seem to have for it. Low-precision training has emerged as a promising answer for efficient coaching (Kalamkar et al., 2019; Narang et al., 2017; Peng et al., 2023b; Dettmers et al., 2022), its evolution being closely tied to developments in hardware capabilities (Micikevicius et al., 2022; Luo et al., 2024; Rouhani et al., 2023a). On this work, we introduce an FP8 mixed precision coaching framework and, for the primary time, validate its effectiveness on an especially giant-scale model.
If you're ready to find more information on
ديب سيك look into our web-page.